
Agathe Balayn
Agathe, can you tell us a little bit about how machine learning systems “learn” and how stereotypes are propagated through these machine learning modes?
Let’s start by explaining first how we use machine learning tools: There are two primary stages, the first stage is training the model and the second is to use it in practice.
To train the model you need to collect data sets full of what you want the model to predict afterwards. For instance, in the context of HR, this could involve compiling CVs of both previously hired individuals and prospective candidates. These datasets serve as the foundation upon which the model will learn. So we have the datasets and then we choose the algorithms which are a set of equations with some parameters that have to be fixed. Then we do what we call “training of the algorithm” which is when you decide on the parameters, using the datasets that we prepared first.
The idea is that, hopefully, in the end, the parameters will represent the content of the datasets we have, so that later on, when using the algorithm with the parameters, it should be capable of making predictions based on new data inputs—such as determining whether a candidate is suitable for hire based on their CV.
I understand that you “feed” the algorithm with data. Therefore, if an individual with biases provides the algorithm with data, will the resulting system also be biased? Where does bias come from?
Typically, we begin with an algorithm containing certain parameters. As we optimize these parameters using the data, we transition to what we call “a model”. The model essentially represents the algorithm with the optimized parameters, derived from the data. Bias can manifest in various ways throughout this process.
One primary source of bias is the data itself used to optimize the parameters, which is collected and processed by individuals. For instance, if the CVs used to supply the dataset with information are predominantly from one demographic group, such as men, while other groups like women or people of color (POC) are underrepresented, the dataset becomes biased. Consequently, when optimizing the algorithm with this biased data, it may fail to effectively predict outcomes for underrepresented groups.
Additionally, the selection of the algorithm and the manner in which data is fed into it can also influence bias. Ultimately, it is the individuals developing the data, algorithm, and model who may inadvertently introduce bias due to their own predispositions or lack of awareness regarding the diversity or representativeness of the data.
In the final step, when creating the model, you require both the data and the fundamental algorithm, and the challenge lies in effectively integrating them. While the data itself can exhibit bias, as we saw, bias can also arise in the process of combining the data with the algorithm. There exist various approaches to this combination, each with its own implications for addressing or perpetuating biases present in the data. Some methods may inadvertently overlook certain biases in the data, while others may be more conscious of potential biases. However, it’s important to recognize that even with awareness of one bias, there are mathematical constraints on what an algorithm can mitigate. For instance, while it may be feasible to mathematically address gender bias, tackling racial bias might pose additional challenges due to the intricate interplay of biases.
How do we currently address the discriminatory impact of AI?
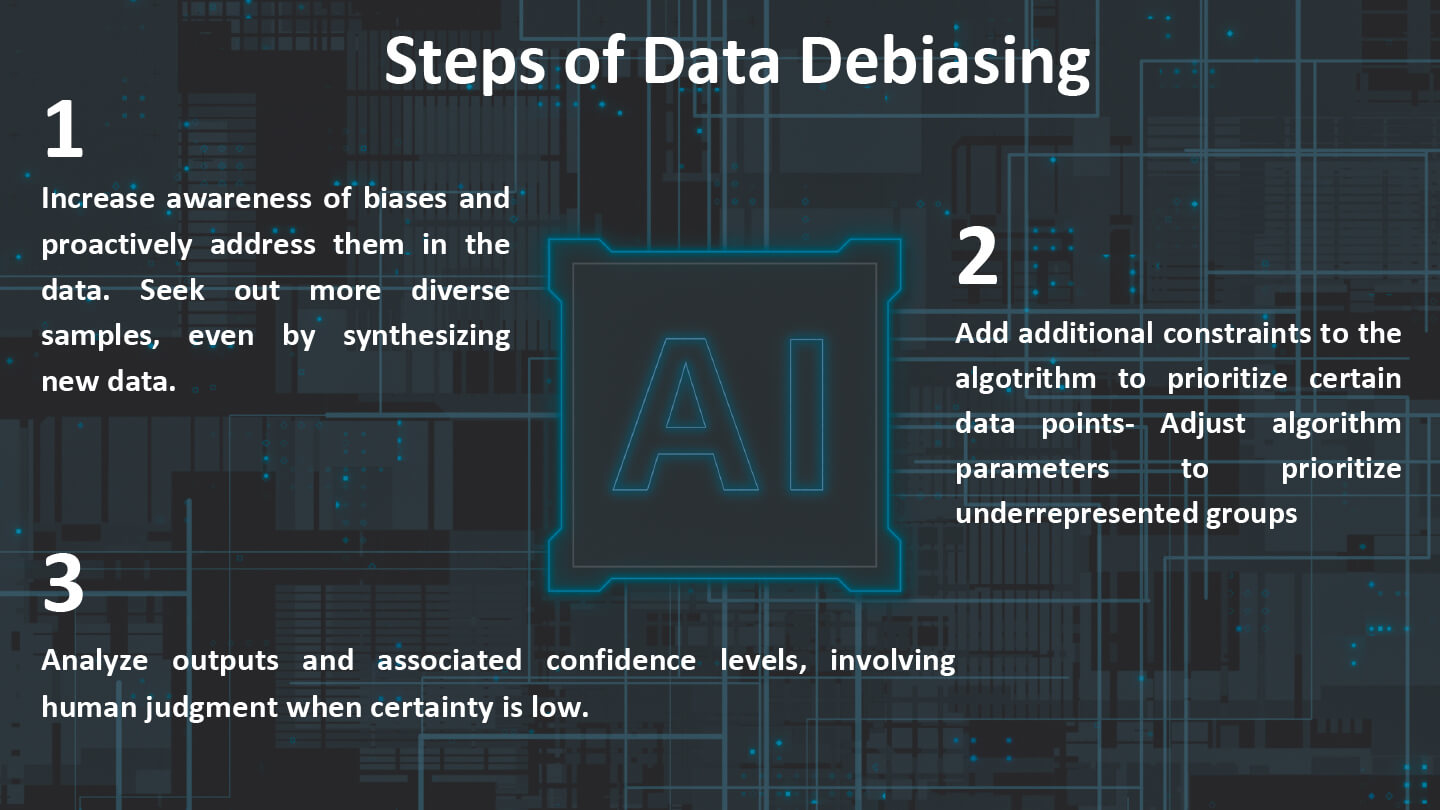
So, because the bias can come from the data, from the algorithm and the way you combine the two, there are the main types of technical methods to debias the model. Some revolve around debiasing the data, some are based on the algorithm and the combination, and lastly, we can debias a model is the post processing of what the model does afterwards, after the creation of the model.
Debiasing the data involves increasing awareness of biases and taking proactive steps to address them. In the example we discussed, this might entail actively seeking out more CVs from women to balance the dataset. In computer science, a common approach is to synthesize new CVs, which involves duplicating existing ones and modifying them to reflect different genders or demographics. By creating synthetic data that closely resembles real-world examples, researchers can augment their dataset with more diverse samples, helping to mitigate biases and improve the overall fairness of the model.
When bias is inherent in the algorithm and its integration with the data, additional constraints can be imposed on the algorithm to ensure it prioritizes certain data points, such as CVs from women. This involves adjusting the parameters of the equation to emphasize the significance of women’s data in the algorithm’s decision-making process.
In the final step of debiasing the model through post-processing, the focus shifts to analyzing the outputs and the associated information provided. Typically, algorithms offer a level of certainty or confidence percentage for the decisions they make. When the certainty percentage is low, it may be prudent to involve human judgment in making the final decision. This step ensures that final human assessment is retained, especially in cases where the algorithm’s confidence in its decision is compromised.
Before creating the model, it’s crucial to establish its general purpose. For example, if the model is intended for CV acceptance or rejection, decisions must be made regarding the type of data to be used. However, obtaining unbiased data can be challenging, especially when attempting to include other non represented groups, let’s say non-binary individuals, in the process. Often, bias is unintentional, stemming from the limited availability of data and societal norms from the past.
An ethical dilemma arises in research areas where attempts are made to predict various characteristics, such as sexual orientation or criminal tendencies, based on biometric data and physical appearance. Such practices raise ethical concerns, as they may lead to unjustified predictions. It is now widely recognized that these characteristics are not significantly correlated with physiognomy or biometrics.
What are the implications of relying solely on debiasing algorithms and datasets to address discrimination in AI, and what alternative approaches could be considered?*
That’s the challenge, in the end we don’t have a good method to develop a model that is unbiased. Unbiased doesn’t really mean anything in practice if you think about it, things are really subjective anyway, and that does mean bias. I’ve heard engineers tell me they are building unbiased GPT’S, removing all hate speech, but what constitutes bias can differ greatly depending on cultural context and legal standards. As a result, achieving complete unbiasedness in models is inherently difficult and subjective.
We do have metrics available to measure the level of bias in models, although they may not be entirely comprehensive. While these metrics may not provide a complete solution, they shouldn’t be disregarded entirely as they can offer some insights. For example, in initiatives like the AI Act, efforts are being made to implement checks and balances. Having metrics allows us to ask important questions and serves as a starting point for addressing bias. The responsibility ultimately lies with developers and decision-makers though. They need to critically evaluate their approaches, question the diversity in the data, and consider how factors like gender are encoded. These decisions require thoughtful reflection and consideration, and while complex algorithms can be useful, they are not a substitute for conscientious design decisions.
Computer scientists often don’t prioritize discussions about bias, as they may not consider it within the scope of their work. They see it more as an ethical issue and believe that decisions related to bias should be made by others, not them. In my interviews with many developers on this topic, I’ve found that a significant number of them work in organizations that lack the resources, time, and decision-making structures necessary for meaningful reflection on these issues.
*Given the limitations of debiasing techniques, policymakers should cease advocating debiasing as the sole response to discriminatory AI, instead promoting debiasing techniques only for the narrow applications for which they are suited- If AI is the problem, is debiasing the solution?
How can policymakers ensure that AI regulation protects, empowers, and holds accountable both organizations and public institutions as they adopt AI-based systems?
Currently, we lack specific measures to address bias in AI systems. While the EU AI Act outlines risk categories, translating these regulations into concrete bias checks presents a challenge. While computational researchers aim to create generalized methods, no one is willing to take sole responsibility for ensuring that these methods are free from bias.
The Act must also maintain a general framework, making it difficult to provide detailed guidance on bias mitigation. Developing standards tailored to various applications is essential, but computational scientists may not be adequately trained to deal with these complexities.
Do both decision-makers and computational scientists need education and awareness regarding bias in AI systems?
Certainly, because decision-makers should understand the importance of allocating resources and providing training for computational infrastructure, even if they don’t fully grasp the technical aspects of data science. Computational scientists, on the other hand, should be aware of the impact of their decisions and may benefit from additional training or guidance on ethical considerations. In some cases, involving third-party companies with expertise in bias mitigation could provide valuable oversight and approval for decisions related to AI systems.
Do you think AI systems, being more “objective”, if regulated and used in the best way, could be allies of diversity, transparency and inclusion in business?
Well, the initial belief was that AI’s objectivity could help mitigate human bias in decision-making processes. And the consistency of decisions made by AI models can indeed contribute to reducing bias compared to human decision-making, provided that the models themselves are carefully designed and trained to be fair and inclusive.
However, it’s essential to ensure that AI systems are developed, deployed, and regulated in a manner that prioritizes ethical considerations, fairness, and transparency. This involves ongoing monitoring, auditing, and updating of AI models to address any biases that may arise and to ensure alignment with organizational values and societal norms regarding diversity and inclusion.
There is this rational worry that AI application reinforces computational infrastructures in the hands of Big Tech and that can influence the regulations around AI.
Of Course, lobbying efforts play a significant role in shaping the standards and requirements surrounding bias audits and regulations within the AI industry. Companies that provide AI models and infrastructure may exert influence over the definition of bias and impartiality based on their own values and social norms. This can result in specific biases being embedded into the algorithms and models they offer, reflecting the perspectives of their developers.
Furthermore, the power dynamics between organizations and AI providers can introduce complexities beyond just bias considerations. Organizations reliant on external AI infrastructure and models may face challenges related to decision-making autonomy, compliance with regulations like GDPR, and overall dependency on the technology provider. These dynamics underscore the importance of transparency, accountability, and ethical oversight in the AI industry to ensure fair and unbiased outcomes.
Also, the use of proprietary data by big tech companies to build AI models raises significant privacy concerns, particularly when these models are tailored for specific organizations. While these companies may have access to vast amounts of data from various sources, including their own platforms and their clients’ data, questions arise regarding the handling and potential sharing of this sensitive information.
For instance, in the case of Large Language Models (LLMs), which require extensive data for training, the aggregation of data from multiple organizations poses risks of data leakage and breaches of confidentiality. Organizations may have legitimate concerns about the privacy and security of their data when it is used in such models, especially if they are unaware of how it will be utilized or shared.
Researchers are actively exploring methods to mitigate these privacy risks, such as techniques for data anonymization, encryption, and differential privacy.

How do you foresee the future in the use of AI tools for businesses?
I think we should take in consideration a lot of things, as beyond the concerns already highlighted, there are additional considerations surrounding the utilization of AI. The extensive data requirements necessitate significant computational power, posing environmental challenges. Moreover, the reliance on crowdworkers for data collection and annotation introduces ethical concerns regarding labor practices. These workers perform crucial tasks, yet their labor may be undervalued and exploitative. Therefore, it is imperative to address not only biases but also the broader ethical and environmental implications of AI deployment. This underscores the need for comprehensive regulation that addresses the diverse array of issues at hand.
In terms of solutions, personally, I would place more trust in a model created by a diverse team or a company that allocates resources and incentives for the development team to engage in reflection and thorough research prior to model creation. Additionally, when it comes to utilizing the model, it’s crucial to consider whether biases are present and whether there are mechanisms in place for secondary human assessment or review to mitigate potential issues.
*Agathe especially talked about questions of bias/fairness in terms of gender, race, etc. But, she did emphasize that some scholars have also investigated the problems related to algorithmic hiring and disabilities https://dl.acm.org/doi/pdf/10.1145/3531146.3533169?casa_token=nK1BJ5PBSBUAAAAA:uz8Ujvc7IUSISZGG2XHSzg1Z0wny2oTAhtGOSMzXrd8D2IGyCoh-M1XNwxivQ2XCDXsnqqKeeOri
Glossary Of Basic Terms
Datasets: A data set (or dataset) is a collection of data.
Algorithm: In mathematics and computer science, an algorithm is a finite sequence of rigorous instructions, typically used to solve a class of specific problems or to perform a computation.Algorithms are used as specifications for performing calculations and data processing.
Parameters: Parameters in machine learning and deep learning are the values your learning algorithm can change independently as it learns and these values are affected by the choice of hyperparameters you provide. So you set the hyperparameters before training begins and the learning algorithm uses them to learn the parameters. Behind the training scene, parameters are continuously being updated and the final ones at the end of the training constitute your model.
Model: The final outcome after training of the algorithm, using parameters and datasets.
Synthetic Data: Synthetic data is information that’s artificially generated rather than produced by real-world events. Typically created using algorithms, synthetic data can be deployed to validate mathematical models and to train machine learning models.
Encoding Gender: In computer technology, encoding is the process of applying a specific code, such as letters, symbols and numbers, to data for conversion into an equivalent cipher.
Crowd Workers: What we call crowdsourcing platforms are platforms where large, distributed groups of workers (named crowd workers) are given “microtasks” to help collect and annotate data intended for training or evaluating AI. On paper, it’s a clever solution to building the datasets quickly and easily given crowdsourcing’s ability to generate custom data on demand and at scale. However, it’s also an often overlooked if critical part of the AI lifecycle, in terms of ethical labor conditions.
ADMS: Automated Decision Making Systems are programmed algorithms that compute data in order to produce an informed automated decision on various matters. ADMS have been used in judicial, government and social services in order to remedy overworked and under-resourced sectors.
